程序在BDS2006下编译通过。
笔者有些懒,理论说明文档就引用网上的。
笔者的代码应该来说是写得比较简单的。
谈Delphi编程中资源文件的应用
一、初级应用篇
资源文件一般为扩展名为res的文件,在VC中资源文件用得非常普遍,但Delphi在其联机帮助中对资源文件没
作什么介绍。其实利用其自带的资源编译工具BRCC32.EXE(一般位于DelphiBIN目录下),我们完全可以做出跟VC一
样效果的文件来。
资源文件最大的好处是能将一些在必要时才调用的文件跟可执行文件一起编译,生成一个文件。这样做最大
的好处就是使外部文件免遭破坏。例如在一个程序中你要临时调用一幅图片,一般作法是把图片放在某一路径下
(通常是主程序所在路径),但如果用户路径误删你的图片文件则可能使程序找不到相应文件而出错崩溃。另外,
如果你想自己的程序界面美观,想用一些自定义光标,也要用到资源文件。
资源文件的使用步骤为:
1.编写rc脚本文本
用记事本或其它文本编辑器编写一个扩展名为rc的文件。例如:
mycur cursor move.cur //加入光标
mypic Bitmap Water.BMP //加入位图
mywav WAVE happy.wav //加入声音
myAVI AVI EPOEN.AVI //加入视频
myIco ICON CJT.ICO //加入图标
格式分别为在资源文件中的名称->类型->实际文件名称,例如上面第一行定义一个名为mycur的光标,实际名
称为加入光标move.cur。
2.将rc文件编译成res资源文件
将脚本文件和实际文件拷到Brcc32.EXE所在目录,执行DOS命令。格式为:Brcc32 脚本文件(回车),例如有
一名为myfirst.rc的脚本文件,则执行Brcc32 myfirst.rc(回车)即可。如果你是懒人,也可新建一批处理文件,
内容只有一行:Brcc32 mufist.rc。(因为Delphi安装后一般会在自动批处理文件中指明搜索路径的)如果编译成
功,则会生成一个结尾为res的文件,这个文件就是我们需要的资源文件。
3.在Delphi单元中加入资源文件
将生成的res资源文件拷贝到你所编程序的路径下,在单元文件{$R *DFM}后加上一句{$R mufirst.res},则
将res文件加入去,编译后资 源文件即已包含在可执行文件中了。若你有多个资源文件,也按上法依次加入。
4.在Delphi程序中调用资源文件
资源文件在Delphi中的关键字为hinstance,下面给出具体用法。
<1>光标的调用
首先在程序中定义一个值大于0的常量,因为Delphi本身用0到负16来索引默认的光标,所以我们制定的光标
应从表面上1开始索引。然后在窗口的Oncreat事件中添加以下代码:screen.cursor[35]:=Loadcursor
(hinstance,'mycur');其中35为大于1的常量,mycur为光标在资源文件中的名字。如果希望在其他控件上使用定制
光标,例如Panel控件,只需在程序的适当处加入以下代码:Panel1.cursor:=35;
<2>位图的调用
新建一项工程,添加一Timage控件,在需要显示的地方写以下代码(其中"mypic"为位图资源文件中的名
称):
Var mymap:Hbitmap;
begin
mymap:=LoadBitmap(hinstance,'mypic');
Image1.picture.Bitmap.Handle:=mymap;
end;
〈3〉AVI文件的调用
新建一工程,添加一Animate控件,在需要的地方加入(其中myAVI为视频文件在资源文件中的名称):
animater1.resname:='myAVI';
animater1.Active:=true;
〈4〉调用WAV文件
在uses中加入mmsystm单元,以便在程序中播放WAV文件。播放时Playsound(pchar
('mywav'),hinstance,sndsync or snd_resource);其中mywav为声音文件在资源中的名称。
〈5〉加入光标
加入光标比较容易,只要将res文件加入单元文件中即可。但需注意,名称最好取"W"."WW"等,使第一个字母
尽量靠后,以免与主程序的图标顺序颠倒。这样一来,别人在使用你的程序时如果想选择其它图标就有很多选择
了。
补充:
1.资源类型除上述类型外,还可以字体文件,字符串文件等;
2.资源文件不但可以在标准图形界面下使用还可在控制台下使用。下面我们来试验一下:新建一工程,将唯
一的一个Form删除,然后修改工程文件。增加一句{$Apptype console},在uses子句中加入mmsystem,并将其它引用
单元删掉。将Begin和end之间语句删掉。至此,我们就可和Turbo PASCAL下编程序一样,且还可以调用windows的
API和资源。将资源文件----{$R myfist.res}加入。在Begin和end之间写下:
writeln('演示程序,按任意键开始!');
readln;
playsound(pchar('mywav'),hinstance,snd_sync or snd_resource);
writeln('演示结束!');
运行程序,将弹出一个标准DOS窗口,按任意键播放声音文件。是不是很COOL呢?我曾下载过一个播放器,在
其安装目录下我发现有一“DOS程序”,用鼠标双击它便弹出一个DOS窗口,显示DOS时代特有的画图,并有背景音
乐!可能就是用这个方法做的。
3.Delphi本身自带了一个叫Image Editor的工具,同样可以编辑资源文本,但和本文的方法比较,可得出下
表:
Image Editor Brcc32
BMP 只支持16位色 任意色
光标 黑白两色 任意色
ICO 只支持16位色 任意色
AVI 不支持 支持
WAV 不支持 支持
字体 不支持 支持
字符串 不支持 支持
上面说的是直接在程序本身的调用。其实资源文件还有其它用法。比如说在你的程序携带其它文件,要用的
时候释放出来。例如:myexe exefile 'ha1.exe'//脚本文件
下面是自定义释放函数ExtractRes,本例中使用如下:ExtractRes('exefile','myexe','c:new.exe');就把
ha1.exe以new.exe为名字保存到C盘根目录下了。
function TForm1.ExtractRes(ResType, ResName, ResNewName: string): boolean;
var
Res: TResourceStream;
begin
try
Res := TResourceStream.Create(Hinstance, Resname, Pchar(ResType));
try
Res.SavetoFile(ResNewName);
Result := true;
finally
Res.Free;
end;
except
Result := false;
end;
二、中级应用篇:
上面我们已经知道如何把一副BMP图像从资源文件里面读出来,但是BMP文件太大了,JPG文件应用的相对较
多。那么如何把JPG图像读出来呢?用资源文件加流方式即可。具体方法如下:
(1)MyJpg JPEG My.JPG
(2)Var
Stream:TStream;
MyJpg:TJpegImage;
Begin
Stream:=TResourceStream.Cceat(HINSTANCE,'MyJpg','JPEG');
Try
MyJpg:=TJpegImage.Create;
Try
MyJpg.LoadfromStream(Stream);
Image1.Picture.Assignc(MyJpg);
Finally
MyJpg.Free;
end;
Finally
Stream.Free;
end;
end;
读取其它图片文件也是一样的。比如说gif动画文件,当然前提是你有一个gif.pas,这个单元很多站点都有
的,可以自己去找找。实际应用中我还发现用上面的代码可以直接显示资源文件中的ICON和BMP。
说到图形处理,实际上还可以用Delphi创建、调用纯图标资源的DLL。比如说你可以看看超级解霸目录下的
Dll,很多就是纯图标资源而已。具体方法如下:
(1)创建一个Hicon.RES文件,这里不再重复;
(2)新建一文本文件Icon.dpr,内容如下:
library Icon;
{$R Icon.RES}
begin
end.
用Delphi打开编译即可得到Icon.dll。
(3)实际调用方法如下:
......
Private
Hinst:THANDLE;
......
Var Hicon:THANDLE;
begin
Hinst:=Loadlibrary('Icon.dll');
If Hinst=0 Then Exit;
Hicon:=Loadicon(Hinst,Pchar(Edit1.Text));
If Hicon<>0 Then Image1.Picture.Icon.Handle:=Hicon;
FreeLibrary(Hinst);
end;
如果你的程序想在国际上供使用不同语言的人使用的话,用Dll来存放字符资源将是一个好方法。因为Dll不
象ini文件那样可以被人随便修改,特别是有时侯如果想保存一些版权信息的话用Dll就再好不过了。比如说你准备
开发一个“汉字简繁体翻译器”软件,准备提供Gb32、Big5码和英文三种语言菜单给用户,那么你可以试试用Dll
来保存字符资源。
我们需要建立三个Dll。第一步当然是写Rc文件,举Gb32码为例,内容如下:
/*MySc.rc*/
#define IDS_MainForm_Caption 1
#define IDS_BtnOpen_Caption 2
#define IDS_BtnSave_Caption 3
#define IDS_BtnBig5_Caption 4
#define IDS_BtnGb32_Caption 5
#define IDS_BtnHelp_Caption 6
#define IDS_Help_Shelp 7
Stringtable
{
IDS_MainForm_Caption,"汉字简繁体翻译器"
IDS_BtnOpen_Caption,"打开文件"
IDS_BtnSave_Caption,"保存文件"
IDS_BtnBig5_Caption,"转换成Big5"
IDS_BtnGb32_Caption,"转换成Gb32"
IDS_BtnHelp_Caption,"帮助"
IDS_Help_Shelp,"输入文字或打开文件后按需要点击按钮即可转换!"
}
另外两个Dll用同样的方法生成。
第二步是Brcc32编译为Res文件后用上面的方法得到Dll文件。下面来应用一下:新建一个工程,放上五个
Button:BtnOpen、BtnSave、BtnBig5、BtnGb32和BtnHelp,还有一个TComboBox:CbSelect用来选择语言种类的。
具体代码如下:
unit Unit1;
interface
......
private
SHelp: string;
function SearchLanguagePack: TStrings;
procedure SetActiveLanguage(LanguageName: string);
{ Private declarations }
......
implementation
procedure TForm1.CbSelectChange(Sender: TObject);
begin
SetActiveLanguage(CbSelect.Text);//调用相应Dll文件读取相应字符.
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
CbSelect.Items.AddStrings(SearchLanguagePack);//搜索当前目录下所有的Dll文件名称
end;
function TForm1.SearchLanguagePack: TStrings;
var
ResultStrings: TStrings;
DosError: integer;
SearchRec: TsearchRec;
begin
ResultStrings := TStringList.Create;
DosError := FindFirst(ExtractFilePath(ParamStr(0)) + '*.dll', faAnyFile, SearchRec);
while DosError = 0 do
begin
ResultStrings.Add(ChangeFileExt(SearchRec.Name, ''));
DosError := FindNext(SearchRec);
end;
FindClose(SearchRec);
Result := ResultStrings;
end;
procedure TForm1.SetActiveLanguage(LanguageName: string);
var
Hdll: Hmodule;
MyChar: array[0..254] of char;
DllFileName: string;
begin
DllFileName := ExtractFilePath(ParamStr(0)) + LanguageName + '.dll';
if not FileExists(DllFileName) then Exit;
Hdll := loadlibrary(Pchar(DllFileName));
Loadstring(hdll, 1, MyChar, 254);
Self.Caption := MyChar;
//读取字符资源,1表示资源文件中定义的1
Loadstring(hdll, 1, MyChar, 254);
Self.Caption := MyChar;
Loadstring(hdll, 2, MyChar, 254);
BtnOpen.Caption := MyChar;
Loadstring(hdll, 3, MyChar, 254);
BtnSave.Caption := MyChar;
Loadstring(hdll, 4, MyChar, 254);
BtnBig5.Caption := MyChar;
Loadstring(hdll, 5, MyChar, 254);
BtnGb32.Caption := MyChar;
Loadstring(hdll, 6, MyChar, 254);
BtnHelp.Caption := MyChar;
Loadstring(hdll, 7, MyChar, 254);
SHelp := MyChar;
Freelibrary(hdll);
Application.Title := Self.Caption;
BtnOpen.Visible := True;
BtnSave.Visible := True;
BtnBig5.Visible := True;
BtnGb32.Visible := True;
BtnHelp.Visible := True;
end;
procedure TForm1.BtnHelpClick(Sender: TObject);
begin
Application.MessageBox(Pchar(SHelp), 'Http://lovejingtao.126.com', MB_ICONINFORMATION);
end;
end.
可能你会说,这种方法还不如我自己在程序中直接定义三种具体的值来的方便。甚至我自己自定义一个结构
好了,用不着用DLL那么麻烦的。但是如果你的程序要用的字符很多呢?比如说Windows操作系统,本身就有简体中
文、繁体中文、英文等版本,用Dll的话只要直接替换DLL即可,而不用每发行一个版本就打开代码来修改一次。这
样一来可以大大减少工作量和出错的机会。
说到这里,再多说一句:Windows系统本身很多Dll带有了图片等资源,我们可以在程序中直接调用,这样一来
我们的EXE也可以减少不少!当然最小的方法是实时生成技术。老外曾经写了一个67KB的程序就是利用了这个方
法,感兴趣的朋友可以到http://go4.163.com/lovejingtao/ha1.exe下载。
三、高级应用篇
Delphi是个很有效率的开发工具,但是它有一个缺点就是生成的EXE文件太大。一个程序就算只有一个空窗口
体积也有286KB。如果直接用API来写的话程序体积是小了,但是又太繁琐,无法立即看到界面效果,根本谈不上是
可视化开发。其实并非“鱼与熊掌不可兼得”,利用资源文件我们就可以轻松达到这个目的。
在开始之前,我们需要一个可以编辑资源文件的工具。这类工具很多,比如说Resource WorkShop就是非常好
的一个。如果一时找不到,利用VC的编辑器来也是可以的。下面我们就以VC的为例示范如何创建一个窗口资源文
件。
运行VC,打开菜单“File/New”,将出现一个多项选择页。我们选择“Files/Resource Template”,在右边
的File填上Demo,Location选择保存路径,然后点击按钮OK返回VC开发环境。
选择菜单“Insert/Resource”,将出现一个资源类型选择框。我们把鼠标移到Dialog上面,不用展开,点击
右边的New即可,这时候返回VC开发环境并出现一个只有关闭按钮和两个Button的窗体。将鼠标选定窗体,击右键
选择最后一项Properties,将出现一个设置窗口,将ID改为“MAINFORM”(注意:跟下面添加的其它控件的属性设
置方法不同,主窗口的ID必须把双引号写上去,而且名称必须为大写。否则程序将找不到资源。程序会一运行就退
出了。)Caption改为“安装程序”,这时候可以立刻看到窗口的标题变成了“安装程序”,把Styles的Minimize
box选上,More Styles的Center勾上使程序运行时的位置居中。当然你也可以设置它的坐标,其它保留默认值即
可。回到开发环境,在控件框里面分别选择一个Static Text,一个Edit Box,一个Button和一个Group Box添加到
窗体上面,把它们按照自己的爱好排列整齐,然后逐个修改它们的属性。方法就是按照上面说的选定控件后击右键
选择最后一项Properties,在出现的属性框里面修改。其中属性如下:Group Box的Caption属性清空,Static
Text的Caption属性改为“请选择安装目录:”,Edit Box的ID改为10001,第一个Button的ID为10002,Caption属
性为“选择”,第二个Button的ID为10003,Caption属性为“安装”,第三个Button的ID为10004,Caption属性为
“退出”。
为了使程序更加完美,我们为它再添加一个菜单IDR_MENU1。选择“Insert/Resource/Menu”,我们这里只简
单添加一项“文件/退出”,其中“退出”的ID为10005。然后在主窗口的属性Menu设定为IDR_MENU1即可。
为了使程序更加美观,我们再添加一个小图标,同时这也将是我们程序的图标。选择
“Insert/Resource/Iconv/Import”,选择一个图标文件,并将它的ID设置为"MAINICON"(注意:必须把双引号写
上而且字母为大写),为窗口添加一个Picture控件并设置它的属性Type:Icon,Image下拉选择刚才的图标MainIcon
即可。
如果你想为程序在鼠标添加一些信息也是可以的。选择“Insert/Resource/Version”即可。到这里我们已经
完成了一个简单的“安装程序”的窗体设计,实际上我们现在就可以在Delphi中调用它了。我们先把“劳动成果”
保存起来,选择“File/Save As”,在文件类型里选择“32-bit Resource File(.res)”保存为“Demo.res”,文
件大小大约为2.65KB。
新建一个扩展名为dpr的文本文件MyDemo.Dpr,键入如下代码:
Uses Windows,Messages;
{$R Demo.Res}
function MainDialogProc(
DlgWin: hWnd;
DlgMessage: UINT;
DlgWParam: WPARAM;
DlgLParam: LPARAM
)
: integer; stdcall;
begin
Result := 0;
case DlgMessage of
WM_Close:
begin
PostQuitMessage(0);
Exit;
end;
end;
end;
begin
DialogBox(hInstance, 'MAINFORM', 0, @MainDialogProc);
end.
用Delphi打开它编译一次即可产生一个大小为19KB的EXE。是不是很小?!实际上,你甚至只用一行代码就把
它Show出来,不过程序无法关闭而已:
Uses Windows;
{$R Demo.Res}
function MainDialogProc: integer;
begin
Result := 0;
end;
begin
DialogBox(hInstance, 'MAINFORM', 0, @MainDialogProc);
end.
上面的程序只不过是一个空窗口而已,现在我们来写代码响应按下相应按钮响应的事件。完整代码如下:
program MyDemo;
uses Windows, Messages, shlobj;
const
ID_Edit = 10001;
ID_Selet = 10002;
ID_Setup = 10003;
ID_Quit = 10004;
ID_Exit = 10005;
{$R Demo.Res}
var
MainWin: HWND;
function My_Gettext: string;
var
Textlength: Integer;
Text: PChar;
s: string;
begin
TextLength := GetWindowTextLength(GetDlgItem(MainWin, ID_Edit));
GetMem(Text, TextLength + 1);
GetWindowText(GetDlgItem(MainWin, ID_Edit), Text, TextLength + 1);
s := text;
FreeMem(Text, TextLength + 1);
Result := s;
end;
function Getmyname: string;
var
i, j: integer;
begin
J := 3;
for i := 1 to length(ParamStr(0)) do
if ParamStr(0)[i] = '' then J := I;
Result := copy(ParamStr(0), J + 1, length(ParamStr(0)) - J);
end;
function SelectDirectory(handle: hwnd; const Caption: string; const Root: WideString; out
Directory: string): Boolean;
var
lpbi: _browseinfo;
buf: array[0..MAX_PATH] of char;
id: ishellfolder;
eaten, att: cardinal;
rt: pitemidlist;
initdir: pwidechar;
begin
result := false;
lpbi.hwndOwner := handle;
lpbi.lpfn := nil;
lpbi.lpszTitle := pchar(caption);
lpbi.ulFlags := BIF_RETURNONLYFSDIRS + BIF_EDITBOX;
SHGetDesktopFolder(id);
initdir := pwchar(root);
id.ParseDisplayName(0, nil, initdir, eaten, rt, att);
lpbi.pidlRoot := rt;
getmem(lpbi.pszDisplayName, MAX_PATH);
try
result := shgetpathfromidlist(shbrowseforfolder(lpbi), buf);
except
freemem(lpbi.pszDisplayName);
end;
if result then
begin
directory := buf;
if length(directory) <> 3 then directory := directory + '';
end;
end;
function MainDialogProc(
DlgWin: hWnd;
DlgMessage: UINT;
DlgWParam: WPARAM;
DlgLParam: LPARAM
)
: integer; stdcall;
var
MyIcon: HICON;
Sdir: string;
begin
Result := 0;
case DlgMessage of
WM_INITDIALOG:
begin
MyIcon := LoadIcon(hInstance, 'MainIcon');
SetClassLONG(DlgWin, GCL_HICON, MyIcon);
MainWin := DlgWin;
end;
WM_Close:
begin
PostQuitMessage(0);
Exit;
end;
WM_COMMAND:
case LOWORD(DlgWParam) of
ID_Selet:
begin
if SelectDirectory(DlgWin, '请选择安装目录', '', Sdir)
then SendMessage(GetDlgItem(DlgWin, ID_Edit), WM_SETTEXT, 0, lParam(pChar
(Sdir)));
end;
ID_Setup:
begin
if My_Gettext = '' then
begin
MessageBox(DlgWin, '请先选择安装文件夹!', '信息', MB_ICONINFORMATION + MB_OK);
Exit;
end;
CopyFile(pchar(ParamStr(0)), pchar(My_Gettext + Getmyname), false);
MessageBox(DlgWin, '安装完毕!', '信息', MB_ICONINFORMATION + MB_OK);
PostQuitMessage(0);
Exit;
end;
ID_Quit:
begin
PostQuitMessage(0);
EXIT;
end;
ID_Exit:
begin
if MessageBox(DlgWin, '你点击了菜单“退出”,你确定退出程序吗?', '信息',
MB_ICONQUESTION + MB_OKCANCEL) = IDOK then
PostQuitMessage(0);
Exit;
end;
end;
end;
end;
begin
DialogBox(hInstance, 'MAINFORM', 0, @MainDialogProc);
end.
Tuesday, May 22, 2007
使用DLL制作插件程序 - Delphi园地
程序在BDS2006下编译通过。
相信各位应该都用过WinAmp,也相信它对插件的支持是它最终流行起来的主要原因。能不能让我们自已的程序也支持插件呢,以面我们就用Delphi来为我们编第一个支持插件的程序。
对于一般用户来说,插件就是一个DLL文件,但与一般DLL不同的是,插件支持对主程序功能的扩展,主程序没有插件也一样能运行,但一般的DLL大多数是主程序不可缺少的部份。当需要经常为客户更新应用程序版本时,插件也许是你不错的选择。
设计思想
主程序每次启动时,在plugins目录下查找所有的*.dll文件(一个*.dll文件就是一个插件),可以同时安装多个插件,数量并无限制,然后将这些插件自动加入主程序的某个菜单项下。
设计插件就预先约定好接口函数,这样才可以方便主程序调用插件,然后将预先约定好的接口公布,以后的程序员只要按此接口编程,便可以调用相应的插件程序。在本例子中,有两个接口函数:
function GetCaption: pchar; stdcall;
function ShowDLLForm(ahandle: thandle; acaption: string): boolean; stdcall;
以后要增加其它新的功能的话,只要把新功能封装成一个DLL方式的插件,然后将这个新生成的*.dll文件放置在plugins目录下即可,而不需要对主 程序作任何的修改或是重新编译主程序,只要重新运行主程序,你将会看到新增加的功能(子程序)已经自动的在主程序的相应菜单项下增加了子菜单项目,现在只 要点击增加的菜单项,就能执行新增加的功能了。这样,对程序的升级来说是不是很方便呢。如果以此种方式来组织架构一套MIS系统,不也是很方便吗?
插件,一种程序设计的即插即用的艺术。
{
Copyrigh 咏南工作室
Author HNXXCXG(大富翁)
QQ 254072148(咏南)
Email hnxxcxg@yahoo.com.cn
Date 12:39 2007-5-7
ToDo
}
相信各位应该都用过WinAmp,也相信它对插件的支持是它最终流行起来的主要原因。能不能让我们自已的程序也支持插件呢,以面我们就用Delphi来为我们编第一个支持插件的程序。
对于一般用户来说,插件就是一个DLL文件,但与一般DLL不同的是,插件支持对主程序功能的扩展,主程序没有插件也一样能运行,但一般的DLL大多数是主程序不可缺少的部份。当需要经常为客户更新应用程序版本时,插件也许是你不错的选择。
设计思想
主程序每次启动时,在plugins目录下查找所有的*.dll文件(一个*.dll文件就是一个插件),可以同时安装多个插件,数量并无限制,然后将这些插件自动加入主程序的某个菜单项下。
设计插件就预先约定好接口函数,这样才可以方便主程序调用插件,然后将预先约定好的接口公布,以后的程序员只要按此接口编程,便可以调用相应的插件程序。在本例子中,有两个接口函数:
function GetCaption: pchar; stdcall;
function ShowDLLForm(ahandle: thandle; acaption: string): boolean; stdcall;
以后要增加其它新的功能的话,只要把新功能封装成一个DLL方式的插件,然后将这个新生成的*.dll文件放置在plugins目录下即可,而不需要对主 程序作任何的修改或是重新编译主程序,只要重新运行主程序,你将会看到新增加的功能(子程序)已经自动的在主程序的相应菜单项下增加了子菜单项目,现在只 要点击增加的菜单项,就能执行新增加的功能了。这样,对程序的升级来说是不是很方便呢。如果以此种方式来组织架构一套MIS系统,不也是很方便吗?
插件,一种程序设计的即插即用的艺术。
{
Copyrigh 咏南工作室
Author HNXXCXG(大富翁)
QQ 254072148(咏南)
Email hnxxcxg@yahoo.com.cn
Date 12:39 2007-5-7
ToDo
}
Monday, May 21, 2007
内核操作 Linux2.6内核驱动移植参考
内核操作 Linux2.6内核驱动移植参考
随 着Linux2.6的发布,由于2.6内核做了教的改动,各个设备的驱动程序在不同程度上要进行改写。为了方便各位Linux爱好者我把自己整理的这分文 档share出来。该文当列举了2.6内核同以前版本的绝大多数变化,可惜的是由于时间和精力有限没有详细列出各个函数的用法。
特别声明:该文档中的内容来自http://lwn.net,该网也上也有各个函数的较为详细的说明可供各位参考。
1、 使用新的入口
必须包含 <linux/init.h>
module_init(your_init_func);
module_exit(your_exit_func);
老版本:int init_module(void);
void cleanup_module(voi);
2.4中两种都可以用,对如后面的入口函数不必要显示包含任何头文件。
2、 GPL
MODULE_LICENSE("Dual BSD/GPL");
老版本:MODULE_LICENSE("GPL");
3、 模块参数
必须显式包含<linux/moduleparam.h>
module_param(name, type, perm);
module_param_named(name, value, type, perm);
参数定义
module_param_string(name, string, len, perm);
module_param_array(name, type, num, perm);
老版本:MODULE_PARM(variable,type);
MODULE_PARM_DESC(variable,type);
4、 模块别名
MODULE_ALIAS("alias-name");
这是新增的,在老版本中需在/etc/modules.conf配置,现在在代码中就可以实现。
5、 模块计数
int try_module_get(&module);
module_put();
老版本:MOD_INC_USE_COUNT 和 MOD_DEC_USE_COUNT
6、 符号导出
只有显示的导出符号才能被其他模块使用,默认不导出所有的符号,不必使用EXPORT_NO_SYMBOLS
老板本:默认导出所有的符号,除非使用EXPORT_NO_SYMBOLS
7、 内核版本检查
需要在多个文件中包含<linux/module.h>时,不必定义__NO_VERSION__
老版本:在多个文件中包含<linux/module.h>时,除在主文件外的其他文件中必须定义__NO_VERSION__,防止版本重复定义。
8、 设备号
kdev_t被废除不可用,新的dev_t拓展到了32位,12位主设备号,20位次设备号。
unsigned int iminor(struct inode *inode);
unsigned int imajor(struct inode *inode);
老版本:8位主设备号,8位次设备号
int MAJOR(kdev_t dev);
int MINOR(kdev_t dev);
9、 内存分配头文件变更
所有的内存分配函数包含在头文件<linux/slab.h>,而原来的<linux/malloc.h>不存在
老版本:内存分配函数包含在头文件<linux/malloc.h>
10、 结构体的初试化
gcc开始采用ANSI C的struct结构体的初始化形式:
static struct some_structure = {
.field1 = value,
.field2 = value,
..
};
老版本:非标准的初试化形式
static struct some_structure = {
field1: value,
field2: value,
..
};
11、 用户模式帮助器
int call_usermodehelper(char *path, char **argv, char **envp,int wait);
新增wait参数
12、 request_module()
request_module("foo-device-%d", number);
老版本:
char module_name[32];
printf(module_name, "foo-device-%d", number);
request_module(module_name);
13、 dev_t引发的字符设备的变化
1、取主次设备号为
unsigned iminor(struct inode *inode);
unsigned imajor(struct inode *inode);
2、老的register_chrdev()用法没变,保持向后兼容,但不能访问设备号大于256的设备。
3、新的接口为
a)注册字符设备范围
int register_chrdev_region(dev_t from, unsigned count, char *name);
b)动态申请主设备号
int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count, char
*name);
看了这两个函数郁闷吧^_^!怎么和file_operations结构联系起来啊?别急!
c)包含 <linux/cdev.h>,利用struct cdev和file_operations连接
struct cdev *cdev_alloc(void);
void cdev_init(struct cdev *cdev, struct file_operations *fops);
int cdev_add(struct cdev *cdev, dev_t dev, unsigned count);
(分别为,申请cdev结构,和fops连接,将设备加入到系统中!好复杂啊!)
d)void cdev_del(struct cdev *cdev);
只有在cdev_add执行成功才可运行。
e)辅助函数
kobject_put(&cdev->kobj);
struct kobject *cdev_get(struct cdev *cdev);
void cdev_put(struct cdev *cdev);
这一部分变化和新增的/sys/dev有一定的关联。
14、 新增对/proc的访问操作
<linux/seq_file.h>
以前的/proc中只能得到string, seq_file操作能得到如long等多种数据。
相关函数:
static struct seq_operations 必须实现这个类似file_operations得数据中得各个成
员函数。
seq_printf();
int seq_putc(struct seq_file *m, char c);
int seq_puts(struct seq_file *m, const char *s);
int seq_escape(struct seq_file *m, const char *s, const char *esc);
int seq_path(struct seq_file *m, struct vfsmount *mnt,
struct dentry *dentry, char *esc);
seq_open(file, &ct_seq_ops);
等等
15、 底层内存分配
1、<linux/malloc.h>头文件改为<linux/slab.h>
2、分配标志GFP_BUFFER被取消,取而代之的是GFP_NOIO 和 GFP_NOFS
3、新增__GFP_REPEAT,__GFP_NOFAIL,__GFP_NORETRY分配标志
4、页面分配函数alloc_pages(),get_free_page()被包含在<linux/gfp.h>中
5、对NUMA系统新增了几个函数:
a) struct page *alloc_pages_node(int node_id,
unsigned int gfp_mask,
unsigned int order);
b) void free_hot_page(struct page *page);
c) void free_cold_page(struct page *page);
6、 新增Memory pools
<linux/mempool.h>
mempool_t *mempool_create(int min_nr,
mempool_alloc_t *alloc_fn,
mempool_free_t *free_fn,
void *pool_data);
void *mempool_alloc(mempool_t *pool, int gfp_mask);
void mempool_free(void *element, mempool_t *pool);
int mempool_resize(mempool_t *pool, int new_min_nr, int gfp_mask);
16、 per-CPU变量
get_cpu_var();
put_cpu_var();
void *alloc_percpu(type);
void free_percpu(const void *);
per_cpu_ptr(void *ptr, int cpu)
get_cpu_ptr(ptr)
put_cpu_ptr(ptr)
老版本使用
DEFINE_PER_CPU(type, name);
EXPORT_PER_CPU_SYMBOL(name);
EXPORT_PER_CPU_SYMBOL_GPL(name);
DECLARE_PER_CPU(type, name);
DEFINE_PER_CPU(int, mypcint);
2.6内核采用了可剥夺得调度方式这些宏都不安全。
17、 内核时间变化
1、现在的各个平台的HZ为
Alpha: 1024/1200; ARM: 100/128/200/1000; CRIS: 100; i386: 1000; IA-64:
1024; M68K: 100; M68K-nommu: 50-1000; MIPS: 100/128/1000; MIPS64: 100;
PA-RISC: 100/1000; PowerPC32: 100; PowerPC64: 1000; S/390: 100; SPARC32:
100; SPARC64: 100; SuperH: 100/1000; UML: 100; v850: 24-100; x86-64: 1000.
2、由于HZ的变化,原来的jiffies计数器很快就溢出了,引入了新的计数器jiffies_64
3、#include <linux/jiffies.h>
u64 my_time = get_jiffies_64();
4、新的时间结构增加了纳秒成员变量
struct timespec current_kernel_time(void);
5、他的timer函数没变,新增
void add_timer_on(struct timer_list *timer, int cpu);
6、新增纳秒级延时函数
ndelay();
7、POSIX clocks 参考kernel/posix-timers.c
18、 工作队列(workqueue)
1、任务队列(task queue )接口函数都被取消,新增了workqueue接口函数
struct workqueue_struct *create_workqueue(const char *name);
DECLARE_WORK(name, void (*function)(void *), void *data);
INIT_WORK(struct work_struct *work,
void (*function)(void *), void *data);
PREPARE_WORK(struct work_struct *work,
void (*function)(void *), void *data);
2、申明struct work_struct结构
int queue_work(struct workqueue_struct *queue,
struct work_struct *work);
int queue_delayed_work(struct workqueue_struct *queue,
struct work_struct *work,
unsigned long delay);
int cancel_delayed_work(struct work_struct *work);
void flush_workqueue(struct workqueue_struct *queue);
void destroy_workqueue(struct workqueue_struct *queue);
int schedule_work(struct work_struct *work);
int schedule_delayed_work(struct work_struct *work, unsigned long
delay);
19、 新增创建VFS的"libfs"
libfs给创建一个新的文件系统提供了大量的API.
主要是对struct file_system_type的实现。
参考源代码:
drivers/hotplug/pci_hotplug_core.c
drivers/usb/core/inode.c
drivers/oprofile/oprofilefs.c
fs/ramfs/inode.c
fs/nfsd/nfsctl.c (simple_fill_super() example)
20、 DMA的变化
未变化的有:
void *pci_alloc_consistent(struct pci_dev *dev, size_t size,
dma_addr_t *dma_handle);
void pci_free_consistent(struct pci_dev *dev, size_t size,
void *cpu_addr, dma_addr_t dma_handle);
变化的有:
1、 void *dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, int flag);
void dma_free_coherent(struct device *dev, size_t size,
void *cpu_addr, dma_addr_t dma_handle);
2、列举了映射方向:
enum dma_data_direction {
DMA_BIDIRECTIONAL = 0,
DMA_TO_DEVICE = 1,
DMA_FROM_DEVICE = 2,
DMA_NONE = 3,
};
3、单映射
dma_addr_t dma_map_single(struct device *dev, void *addr,
size_t size,
enum dma_data_direction direction);
void dma_unmap_single(struct device *dev, dma_addr_t dma_addr,
size_t size,
enum dma_data_direction direction);
4、页面映射
dma_addr_t dma_map_page(struct device *dev, struct page *page,
unsigned long offset, size_t size,
enum dma_data_direction direction);
void dma_unmap_page(struct device *dev, dma_addr_t dma_addr,
size_t size,
enum dma_data_direction direction);
5、有关scatter/gather的函数:
int dma_map_sg(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction direction);
void dma_unmap_sg(struct device *dev, struct scatterlist *sg,
int nhwentries, enum dma_data_direction direction);
6、非一致性映射(Noncoherent DMA mappings)
void *dma_alloc_noncoherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, int flag);
void dma_sync_single_range(struct device *dev, dma_addr_t dma_handle,
unsigned long offset, size_t size,
enum dma_data_direction direction);
void dma_free_noncoherent(struct device *dev, size_t size,
void *cpu_addr, dma_addr_t dma_handle);
7、DAC (double address cycle)
int pci_dac_set_dma_mask(struct pci_dev *dev, u64 mask);
void pci_dac_dma_sync_single(struct pci_dev *dev,
dma64_addr_t dma_addr,
size_t len, int direction);
21、 互斥
新增seqlock主要用于:
1、少量的数据保护
2、数据比较简单(没有指针),并且使用频率很高
3、对不产生任何副作用的数据的访问
4、访问时写者不被饿死
<linux/seqlock.h>
初始化
seqlock_t lock1 = SEQLOCK_UNLOCKED;
或seqlock_t lock2; seqlock_init(&lock2);
void write_seqlock(seqlock_t *sl);
void write_sequnlock(seqlock_t *sl);
int write_tryseqlock(seqlock_t *sl);
void write_seqlock_irqsave(seqlock_t *sl, long flags);
void write_sequnlock_irqrestore(seqlock_t *sl, long flags);
void write_seqlock_irq(seqlock_t *sl);
void write_sequnlock_irq(seqlock_t *sl);
void write_seqlock_bh(seqlock_t *sl);
void write_sequnlock_bh(seqlock_t *sl);
unsigned int read_seqbegin(seqlock_t *sl);
int read_seqretry(seqlock_t *sl, unsigned int iv);
unsigned int read_seqbegin_irqsave(seqlock_t *sl, long flags);
int read_seqretry_irqrestore(seqlock_t *sl, unsigned int iv, long
flags);
22、 内核可剥夺
<linux/preempt.h>
preempt_disable();
preempt_enable_no_resched();
preempt_enable_noresched();
preempt_check_resched();
23、 眠和唤醒
1、原来的函数可用,新增下列函数:
prepare_to_wait_exclusive();
prepare_to_wait();
2、等待队列的变化
typedef int (*wait_queue_func_t)(wait_queue_t *wait,
unsigned mode, int sync);
void init_waitqueue_func_entry(wait_queue_t *queue,
wait_queue_func_t func);
24、 新增完成事件(completion events)
<linux/completion.h>
init_completion(&my_comp);
void wait_for_completion(struct completion *comp);
void complete(struct completion *comp);
void complete_all(struct completion *comp);
25、 RCU(Read-copy-update)
rcu_read_lock();
void call_rcu(struct rcu_head *head, void (*func)(void *arg),
void *arg);
26、 中断处理
1、中断处理有返回值了。
IRQ_RETVAL(handled);
2、cli(), sti(), save_flags(), 和 restore_flags()不再有效,应该使用local_save
_flags() 或local_irq_disable()。
3、synchronize_irq()函数有改动
4、新增int can_request_irq(unsigned int irq, unsigned long flags);
5、 request_irq() 和free_irq() 从 <linux/sched.h>改到了 <linux/interrupt.h>
27、 异步I/O(AIO)
<linux/aio.h>
ssize_t (*aio_read) (struct kiocb *iocb, char __user *buffer,
size_t count, loff_t pos);
ssize_t (*aio_write) (struct kiocb *iocb, const char __user *buffer,
size_t count, loff_t pos);
int (*aio_fsync) (struct kiocb *, int datasync);
新增到了file_operation结构中。
is_sync_kiocb(struct kiocb *iocb);
int aio_complete(struct kiocb *iocb, long res, long res2);
28、 网络驱动
1、struct net_device *alloc_netdev(int sizeof_priv, const char *name,
void (*setup)(struct net_device *));
struct net_device *alloc_etherdev(int sizeof_priv);
2、新增NAPI(New API)
void netif_rx_schedule(struct net_device *dev);
void netif_rx_complete(struct net_device *dev);
int netif_rx_ni(struct sk_buff *skb);
(老版本为netif_rx())
29、 USB驱动
老版本struct usb_driver取消了,新的结构体为
struct usb_class_driver {
char *name;
struct file_operations *fops;
mode_t mode;
int minor_base;
};
int usb_submit_urb(struct urb *urb, int mem_flags);
int (*probe) (struct usb_interface *intf,
const struct usb_device_id *id);
30、 block I/O 层
这一部分做的改动最大。不祥叙。
31、 mmap()
int remap_page_range(struct vm_area_struct *vma, unsigned long from,
unsigned long to, unsigned long size,
pgprot_t prot);
int io_remap_page_range(struct vm_area_struct *vma, unsigned long from,
unsigned long to, unsigned long size,
pgprot_t prot);
struct page *(*nopage)(struct vm_area_struct *area,
unsigned long address,
int *type);
int (*populate)(struct vm_area_struct *area, unsigned long address,
unsigned long len, pgprot_t prot, unsigned long pgoff,
int nonblock);
int install_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long addr, struct page *page,
pgprot_t prot);
struct page *vmalloc_to_page(void *address);
32、 零拷贝块I/O(Zero-copy block I/O)
struct bio *bio_map_user(struct block_device *bdev,
unsigned long uaddr,
unsigned int len,
int write_to_vm);
void bio_unmap_user(struct bio *bio, int write_to_vm);
int get_user_pages(struct task_struct *task,
struct mm_struct *mm,
unsigned long start,
int len,
int write,
int force,
struct page **pages,
struct vm_area_struct **vmas);
33、 高端内存操作kmaps
void *kmap_atomic(struct page *page, enum km_type type);
void kunmap_atomic(void *address, enum km_type type);
struct page *kmap_atomic_to_page(void *address);
老版本:kmap() 和 kunmap()。
34、 驱动模型
主要用于设备管理。
1、 sysfs
2、 Kobjects(T002)
Friday, May 18, 2007
Socket Buffers - The Linux Networking Architecture
4.1 Socket Buffers
The network implementation of Linux is designed to be independent of a specific protocol. This applies both to the network and transport layer protocols (TCIP/IP, IPX/SPX, etc.) and to network adapter protocols (Ethernet, token ring, etc.). Other protocols can be added to any network layer without a need for major changes. As mentioned before, socket buffers are data structures used to represent and manage packets in the Linux kernel.
A socket buffer consists of two parts (shown in Figure 4-1):
-
Packet data: This storage location stores data actually transmitted over a network. In the terminology introduced in Section 3.2.1, this storage location corresponds to the protocol data unit.
-
Management data (struct sk_buff): While a packet is being processed in the Linux kernel, the kernel requires additional data that are not necessarily stored in the actual packet. These mainly implementation-specific data (pointers, timers, etc.). They form part of the interface control information (ICI) exchanged between protocol instances, in addition to the parameters passed in function calls.
Figure 4-1. Structure of socket buffers (struct sk_buff) with packet storage locations.

The socket buffer is the structure used to address and manage a packet over the entire time this packet is being processed in the kernel. When an application passes data to a socket, then the socket creates an appropriate socket buffer structure and stores the payload data address in the variables of this structure. During its travel across the layers (see Figure 4-2), packet headers of each layer are inserted in front of the payload. Sufficient space is reserved for packet headers that multiple copying of the payload behind the packet headers is avoided (in contrast to other operating systems). The payload is copied only twice: once when it transits from the user address space to the kernel address space, and a second time when the packet data is passed to the network adapter. The free storage space in front of the currently valid packet data is called headroom, and the storage space behind the current packet data is called tailroom in Linux.
Figure 4-2. Changes to the packet buffers across the protocol hierarchy.

When a packet is received over a network adapter, the method dev_alloc_skb() is used to request an sk_buff structure during the interrupt handling. This structure is then used to store the data from the received packet. Until it is sent, the packet is always addressed over the socket buffer created.
We now explain briefly the parameters of the sk_buff structure (Figure 4-3):
-
next, prev are used to concatenate socket buffers in queues (struct skb_queue_head). They should always be provided by special functions available to process socket buffers (skb_queue_head(), skb_dequeue_tail(), etc.) and should not be changed directly by programmers. These operations will be introduced in Section 4.1.1.
-
list points to the queue where the socket buffer is currently located. For this reason, queues should always be of the type struct sk_buff_head, so that they can be managed by socket buffer operations. This pointer should point to null for a packet not assigned to any queue.
-
sk points to the socket that created the packet. For a software router, the driver of the network adapters creates the socket buffer structure. This means that the packet is not assigned to a valid socket, and so the pointer points to null.
-
stamp specifies the time when the packet arrived in the Linux system (in jiffies).
-
dev and rx_dev are references to network devices, where dev states the current network device on which the socket buffer currently operates. Once the routing decision has been taken, dev points to the network adapter over which the packet should leave the computer. Until the output adapter for the packet is known, dev points to the input adapter. rx_dev always points to the network device that received the packet.
Figure 4-3. The sk_buff structure, including management data for a packet.
struct sk_buff
{
struct sk_buff *next,*prev;
struct sk_buff_head *list;
struct sock *sk;
struct timeval stamp;
struct net_device *dev, *rx_dev;
union /* Transport layer header */
{
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct spxhdr *spxh;
unsigned char *raw;
} h;
union /* Network layer header */
{
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
struct ipxhdr *ipxh;
unsigned char *raw;
} nh;
union /* Link layer header */
{
struct ethhdr *ethernet;
unsigned char *raw;
} mac;
struct dst_entry *dst;
char cb[48];
unsigned int len, csum;
volatile char used;
unsigned char is_clone, cloned, pkt_type, ip_summed;
__u32 priority;
atomic_t users;
unsigned short protocol, security;
unsigned int truesize;
unsigned char *head, *data, *tail, *end;
void (*destructor)(struct sk_buff *);
...
};
-
h, nh, and mac are pointers to packet headers of the transport layer (h), the network layer (nh), and the MAC layer (mac). These pointers are set for a packet as it travels across the kernel. (See Figure 4-2.) For example, the h pointer of an IP packet is set in the function ip_rcv() to the IP protocol header (type iphdr).
-
dst refers to an entry in the routing cache, which means that it contains either information about the packet's further trip (e.g., the adapter over which the packet is to leave the computer) or a reference to a MAC header stored in the hard header cache. (See Chapters 15 and 16a.)
-
cloned indicates that a packet was cloned. Clones will be explained in detail later in this chapter. For now, it is sufficient to understand that clones are several copies of a packet and that, though several sk_buff structures exist for a packet, they all use one single packet data location jointly.
-
pkt_type specifies the type of a packet, which can be one of the following:
-
PACKET_HOST specifies packet a sent to the local host.
-
PACKET_BROADCAST specifies a broadcast packet.
-
PACKET_MULTICAST specifies a multicast packet.
-
PACKET_OTHERHOST specifies packets not destined for the local host, but received by special modes (e.g., the promiscuous mode).
-
PACKET_OUTGOING specifies packets leaving the computer.
-
PACKET_LOOPBACK specifies packets sent from the local computer to itself.
-
PACKET_FASTROUTE specifies packets fast-forwarded between special network cards (fastroute is not covered in this book).
-
-
len designates the length of a packet represented by the socket buffer. This considers only data accessible to the kernel. This means that only the two MAC addresses and the type/length field are considered in an Ethernet packet. The other fields (preamble, padding, and checksum) are added later in the network adapter, which is the reason why they are not handled by the kernel.
-
data, head, tail, end: The data and tail pointers point to currently valid packet data. Depending on the layer that currently handles the packet, these parameters specify the currently valid protocol data unit.
head and end point to the total location that can be used for packet data. The latter storage location is slightly bigger to allow a protocol to add protocol data before or after the packet, without the need to copy the packet data. This avoids expensive copying of the packet data location. If it has to be copied in rare cases, then appropriate methods can be used to create more space for packet data.
The space between head and data is called headroom; the space between tail and end is called tailroom.
-
The other parameters are not discussed here, because they are of minor importance. Some of them are discussed in other chapters (e.g., netfilter in Section 19.3).
The pointer datarefp is actually not part of the sk_buff structure, because it is located at the end of the packet data space and not defined as a variable of a structure. (See Figure 4-1.) datarefp is a reference counter; it can be easily addressed and manipulated by use of the macro skb_datarefp(skb).
The reference counter was arranged in this way because, during cloning of socket buffers, several sk_buff structures will still point to the same packet data space. If a socket buffer is released, then no other references to the packet data space should also release the packet data space. Otherwise, this would quickly lead to a huge storage hole. The only location where the number of references to packet data can be managed is the packet data space itself, because there is no list managing all clones of a packet. For this reason, and to avoid having to create another data type, we simply reserve a few more bytes than specified by the user when allocating the packet data space. Using the macro skb_datarefp, it is easy to access and test the reference counter to see whether there are other references to the packet data space, in addition to the own reference.
4.1.1 Operations on Socket Buffers
The Linux kernel offers you a number of functions to manipulate socket buffers. In general, these functions can be grouped into three categories:
-
Create, release, and duplicate socket buffers: These functions assume the entire storage management for socket buffers and their optimization by use of socket-buffer caches.
-
Manipulate parameters and pointers within the sk_buff structure: These mainly are operations to change the packet data space.
-
Manage socket buffer queues.
Creating and Releasing Socket Buffers
| alloc_skb() | net/core/skbuff.c |
In the creation of a new socket buffer, no immediate attempt is made to allocate the memory with kmalloc() for the sk_buff structure; rather, an attempt is made to reuse previously consumed sk_buff structures. Note that requesting memory in the kernel's storage management is very expensive and that, because structures of the same type always require the same size, an attempt is first made to reuse an sk_buff structure no longer required. (This approach can be thought of as simple recycling; see Section 2.6.2.)
There are two different structures that manage consumed socket buffer structures:
-
First, each CPU manages a so-called skb_head_cache that stores packets no longer needed. This is a simple socket buffer queue, from which alloc_skb() takes socket buffers.
-
Second, there is a central stack for consumed sk_buff structures (skbuff_head_cache).
If there are no more sk_buff structures available for the current CPU, then kmem_cache_alloc() is used to try obtaining a packet from the central socket-buffer cache (skbuff_head_cache). If this attempt fails, then kmalloc() is eventually used. gfp_mask contains flags required to reserve memory.
Using these two caches can be justified by the fact that many packets are created and released in a system (i.e., the memory of sk_buff structures is frequently released), only to be required again shortly afterwards. The two socket buffer caches were introduced to avoid this expensive releasing and reallocating of memory space by the storage management (similarly to first-level and second-level caches for CPU memory access). This means that the time required to release and reserve sk_buff structures can be shortened. When kmem_cache_alloc() is used to reserve an sk_buff structure, the function skb_header_init() is called to initialize the structure. It will be described further below.
Naturally, for the sk_buff structure, a socket buffer requires memory for the packet data. Because the size of a packet is usually different from and clearly bigger than that of an sk_buff structure, a method like the socket-buffer cache does not provide any benefit. The packet data space is reserved in the usual way (i.e., by use of kmalloc()).
The pointers head, data, tail, and end are set once memory has been reserved for the packet data. The counters user and datarefp (number of references to these socket buffer structure) are set to one. The data space for packets begins to grow from the top (data) (i.e., at that point, the socket buffer has no headroom and has tailroom of size bytes).
| dev_alloc_skb() | include/linux.skbuff.h |
| skb_copy() | net/core/skbuff.c |
Figure 4-4. Copying socket buffers.

Memory needed for the payload of the new socket buffers is allocated by kmalloc() and copied by memcopy(). Subsequently, pointers to the new data space are set in the new sk_buff structure. The result of skb_copy() is a new socket buffer (with its own packet data space), which exists independently of the original and can be processed independently. This means that the reference counter of the created copy also shows a value of one, in contrast to a using skb_clone() to replicate a packet.
| skb_copy_expand() | net/core/skbuff.c |
| skb_clone() | net/core/skbuff.c |
Figure 4-5 shows the situation before and after skb_clone() is called. Among other things, this function is required in multicast implementation. (See Chapter 17.) This allows us to prevent the time-intensive copying of a complete packet data space when a packet is to be sent to several network devices. The memory containing packet data is not released before the variable datarefp contains a value of one (i.e., when there is only one reference to the packet data space left).
Figure 4-5. Cloning socket buffers.

| kfree_skb() | include/linux/skbuff.h |
| include/linux/skbuff.h |
| kfree_skbmem() | include/linux/skbuff.h |
| skb_header_init() | include/linux/skbuff.h |
Manipulating the Packet Data Space
The following functions are declared in the include file
| include/linux/skbuff.h |
| skb_unshare() | include/linux/skbuff.h |
| skb_put() | include/linux/skbuff.h |
| skb_push() | include/linux/skbuff.h |
| skb_pull() | include/linux/skbuff.h |
| skb_tailroom() | include/linux/skbuff.h |
| include/linux/skbuff.h |
| skb_realloc_headroom() | include/linux/skbuff.h |
| skb_reserve() | include/linux/skbuff.h |
skb_reserve(skb, len) shifts the entire current data space backwards by len bytes. This means that the total length of this space remains the same. Of course, this function is meaningful only when there are no data in the current space yet, and only if the initial occupancy of this space has to be corrected.
| skb_trim() | include/linux/skbuff.h |
skb_trim(skb, len) sets the current packet data space to len bytes, which means that this space now extends from the initial occupancy of data to tail - data + len. This function is normally used to truncate data at the end (i.e., we call skb_trim() with a length value smaller than the current packet size).
| skb_cow() | include/linux/skbuff.h |
4.1.2 Other Functions
| skb_cloned() | include/linux/skbuff.h |
skb_cloned(skb) specifies whether this socket buffer was cloned and whether the corresponding packet data space is exclusive. The reference counter datarefp is used to check this.
| include/linux/skbuff.h |
skb_shared(skb) checks whether skb?gt;users specifies one single user or several users for the socket buffer.
| skb_over_panic(), skb_under_panic() | include/linux/skbuff.h |
| skb_head_to_pool() | net/core/skbuff.c |
The queue skb_head_pool[smp_processor_id()].list cannot grow to an arbitrary length; it can contain a maximum of sysctl_hot_list_len. As soon as this size is reached, additional socket buffers are added to the central pool for reusable socket buffers (skbuff_head_cache).
| skb_head_from_pool() | net/core/skbuff.c |
This function is used to remove and return a socket buffer from the pool of used socket buffers of the current processor.
Subscribe to:
Posts (Atom)
如何发掘出更多退休的钱?
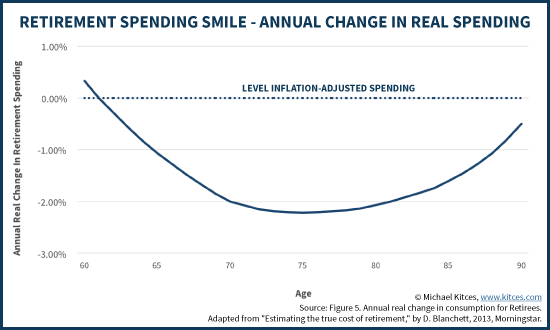
如何发掘出更多退休的钱? http://bbs.wenxuecity.com/bbs/tzlc/1328415.html 按照常规的说法,退休的收入必须得有退休前的80%,或者是4% withdrawal rule,而且每年还得要加2-3%对付通胀,这是一个很大...
-
魏杰教授这篇演讲,深入浅出,把未来几年的经济形势讲的非常透彻。 魏杰:我和大家一起对未来一段时间做一个交流,可能在座的知道从2018年3月份开始,中国社会生活出现了六个很严重的现象。 第一个现象 ,大量的中小企业反映企业非常难做,压力很大。既有成本压力,也有资金...
-
以下内容摘编自中文版《如何让孩子成年又成人》。 1. 另辟蹊径 我们都希望孩子在离家的时候,可以产生 “我觉得我可以,我觉得我行” 的心态。 这种心态的另一种表述是 “自我效能” 。它意味着相信自己有能力完成任务、实现目标及把把控局面。它意味着你相信自己做事情的能...
-
如何发掘出更多退休的钱? http://bbs.wenxuecity.com/bbs/tzlc/1328415.html 按照常规的说法,退休的收入必须得有退休前的80%,或者是4% withdrawal rule,而且每年还得要加2-3%对付通胀,这是一个很大...

